
AI鮎川まどか最新番号,还是斩获了IMO奥数银牌!
就在刚刚,谷歌DeepMind晓示:本年国外数学奥林匹克竞赛的真题,被自家的AI系统作念出来了。
其中,AI不仅得手完成了6说念题中的4说念,并且每说念题齐取得了满分,相配于是银牌的最高分——28分。
这个得益,距离金牌只须1分之遥!
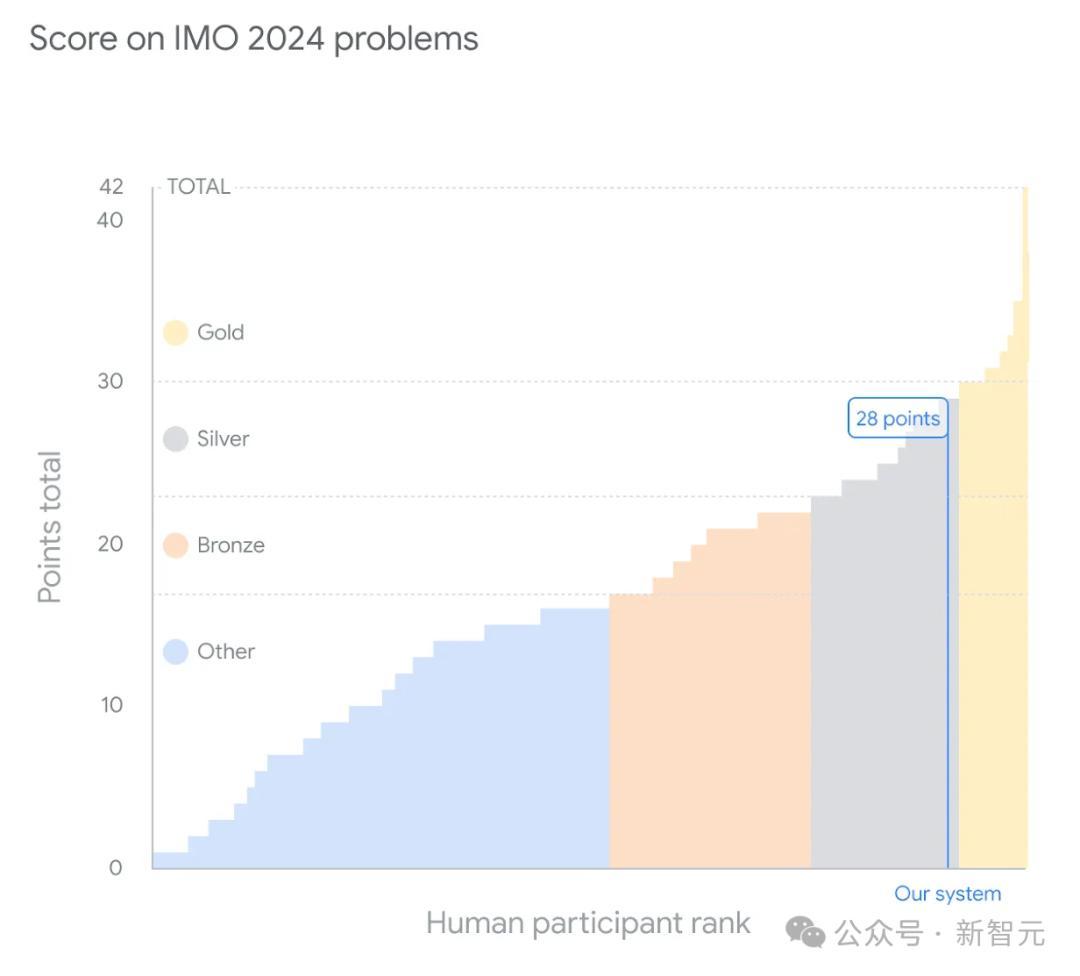
609名参赛选手中,拿到金牌的只须58东说念主
在肃穆比赛中,东说念主类选手会分两次提交谜底,每次限时4.5小时。
酷爱酷爱酷爱酷爱的是,AI只用了几分钟便答出了其中沿途,但剩下的问题却花了整整三天时辰,不错说是严重超时了。
精选嫩鲍
此次立下大功的,是两款AI系统——AlphaProof和AlphaGeometry 2。
划要点:2024 IMO并不在这两个AI的西宾数据中。
其实,早在本年1月份,谷歌DeepMind的第一代AlphaGeometry就登上了Nature。其时,它作念出了IMO 30个几何题中的25说念。
AI工程师Devin背后独创东说念主之一Scott Wu(IOI三枚金牌得主)感慨说念,「当我照旧个孩子的时候,奥林匹克竞赛就是我的全部。从来莫得想过,只是10年后,它们就被AI惩处了」。

本年的IMO竞赛上,共有六说念赛题,波及代数、组合学、几何和数论。六说念作念出四说念,让咱们感受一下AI的水平——


AI的数学推明智力,战栗评分陶冶
咱们齐知说念,以前的AI在惩处数学问题上一直衣衫不整,原因在于推明智力和西宾数据的截至。
而今天联袂登场的两位AI选手,则龙套了这种截至。它们分手是——
- AlphaProof,基于强化学习的步地数学推理新系统
- AlphaGeometry 2,第二代几何解题系统
两位AI给出的谜底,由有名数学家Timothy Gowers陶冶(IMO金牌得主和菲尔兹奖得主)和Joseph Myers博士(两次IMO金牌得主、IMO 2024问题采用委员会主席),凭证法例进行评分。
最终,AlphaProof正确作念出两个代数题和一个数论题,其中一个最难的问题,在本年IMO中只须5名东说念主类参赛者作念了出来;AlphaGeometry 2则作念出了沿途几何题。
莫得被攻克的,只须两说念组合数学题。
Timothy Gowers陶冶在评分的过程中,也被深深地震憾了——
轨范或者建议这么一个非不言而谕的解法,真的令东说念主印象深远,远超出我对现时技巧水平的预期。

AlphaProof
AlphaProof是一个或者在步地化讲话Lean中讲授数学命题的系统。
它聚拢了预西宾的大讲话模子和AlphaZero强化学习算法,后者曾自学掌合手了国外象棋、将棋和围棋。
步地化讲话的一个要道上风,就是不错对波及数学推理的讲授进行步地化考据。但是,由于东说念主类编写的关联数据量特殊有限,它们在机器学习中的应用一直受到截至。
比拟之下,基于当然讲话的按序尽管不错探听大齐数据,但却可能产生不足为训、但不正确的中间推理设施和惩处决议。
为了克服这极少,谷歌DeepMind商量者通过微调Gemini模子,将当然讲话问题述说自动翻译成步地化述说,成立了一个包含不同难度的步地化问题的大型库,从而在两个互补规模之间架起桥梁。
解题时,AlphaProof会生成候选的惩处决议,并通过在Lean中搜索可能的讲授设施,来讲授或反驳它们。
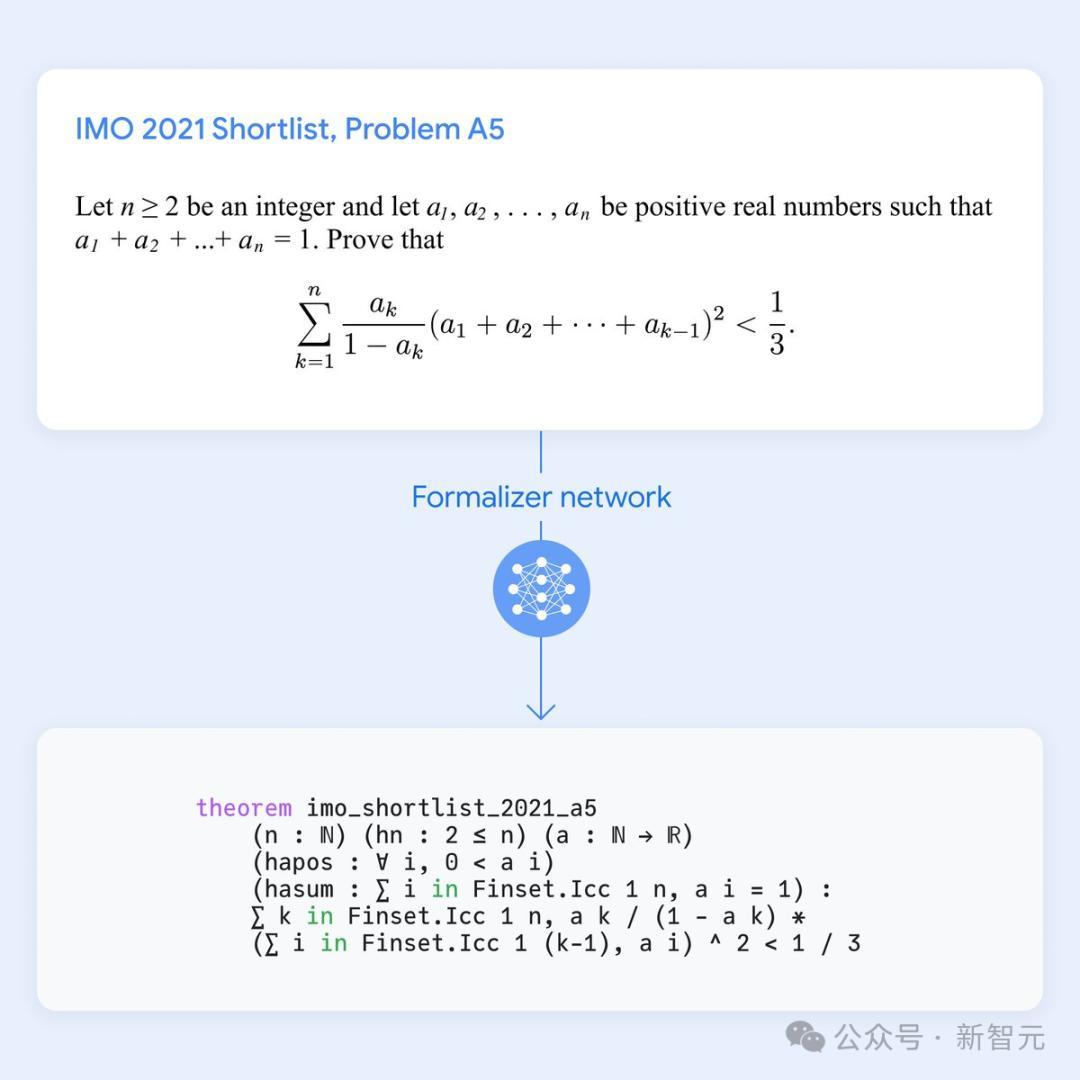
每个被找到并考据的讲授,齐被用于强化AlphaProof的讲话模子,让它不错在后续惩处更难的问题。
为了西宾AlphaProof,商量者讲授或反驳了几百万个问题,涵盖了从比赛前几成全比赛时间庸俗的难度和数学主题规模。
在比赛时间,他们还应用了西宾轮回,通过强化自生成的比赛问题变体的讲授,直到找到完好的惩处决议。
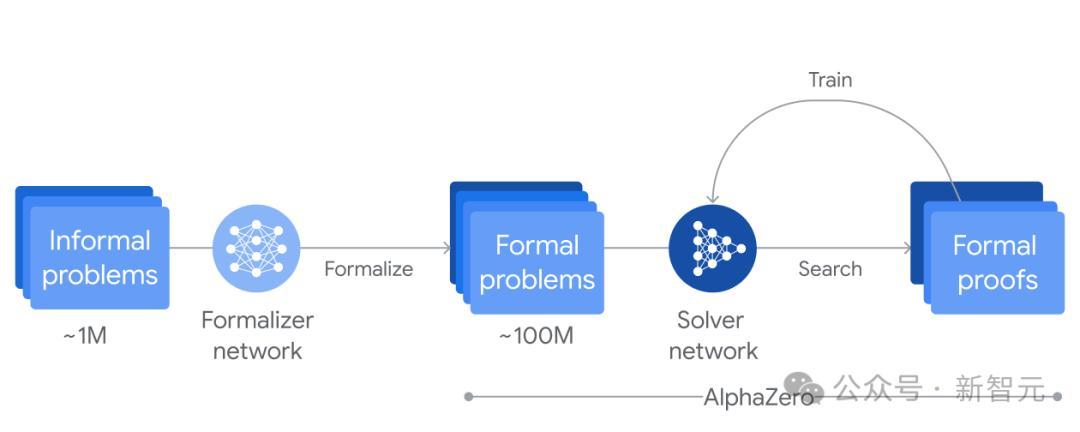
AlphaProof强化学习西宾轮回的经过信息图:约莫一百万个非肃穆数学问题由步地化网罗翻译成步地化数学讲话;接着,求解网罗通过搜索这些问题的讲授或反驳,并诈欺AlphaZero算法冉冉西宾我方,以惩处更具挑战性的问题
AlphaGeometry 2
AlphaGeometry的升级版AlphaGeometry 2,是一个神经符号羼杂系统,基于Gemini的讲话模子从新启动西宾。
基于比上一代多了一个数目级的合成数据,它或者作念出难度更高的几何问题,包括波及物体畅通、角度、比例和距离方程等等。
此外,它还接管了比前一代快两个数目级的符号引擎。当遭遇新问题时,它会用一种新颖的学问分享机制,使不同搜索树的高档组合或者惩处更复杂的问题。
在本年参赛IMO之前,AlphaGeometry 2还是战绩累累:它能作念出畴昔25年IMO几何赛题中的83%,而第一代只可作念出53%。
在这届IMO中,AlphaGeometry 2的骁勇速率更是战栗了世东说念主——在接管到步地化问题的19秒内,它就把问题4作念出来了!
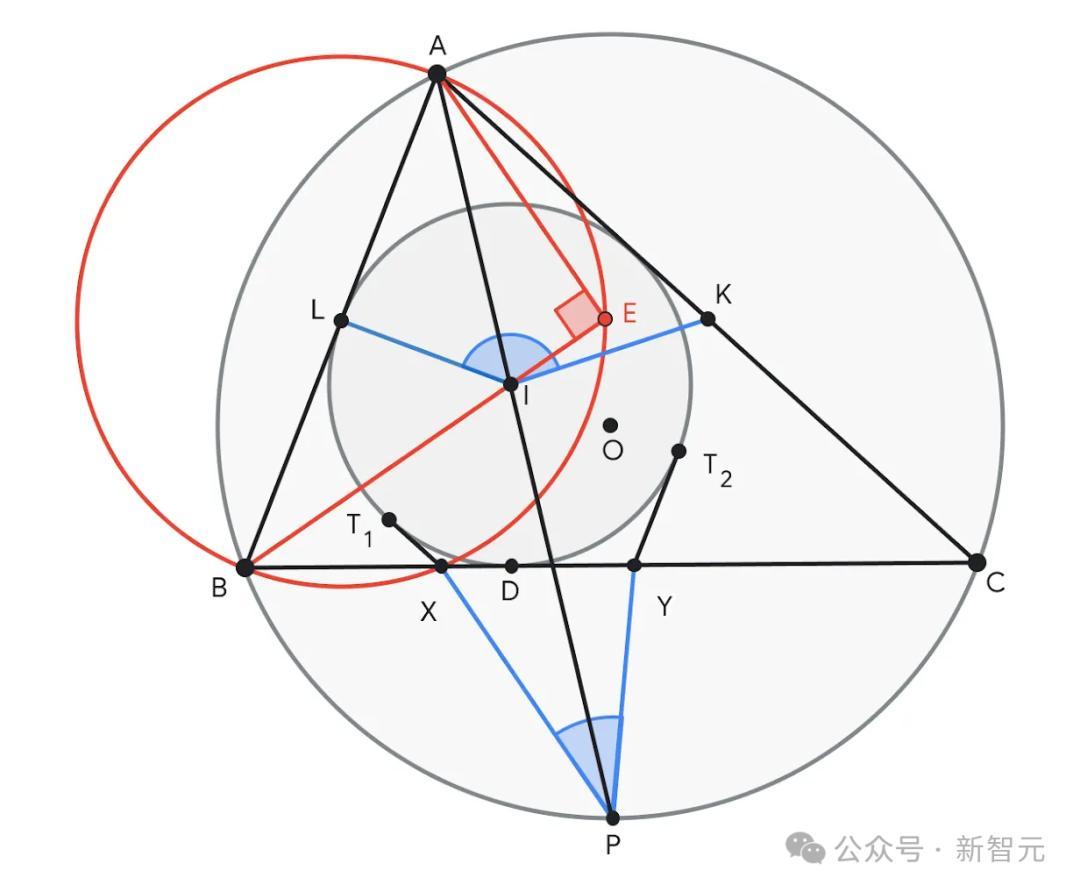
问题4要求讲授∠KIL和∠XPY之和等于180°。AlphaGeometry 2建议在BI线上构造一个点E,使得∠AEB=90°。点E有助于详情AB的中点L,酿成了好多近似的三角形对,如ABE ~ YBI和ALE ~ IPC,从而讲授论断
AI的解题过程
值得一提的是,这些问题最初会被东说念主工翻译成肃穆的数学讲话,然后才会投给AI。
P1
一般来说,每届IMO试题中第一题(P1)相对来说,是比较容易的。
网友暗示,「P1仅需要高中数学学问就够了,东说念主类选手频频会在60分钟内完成」。
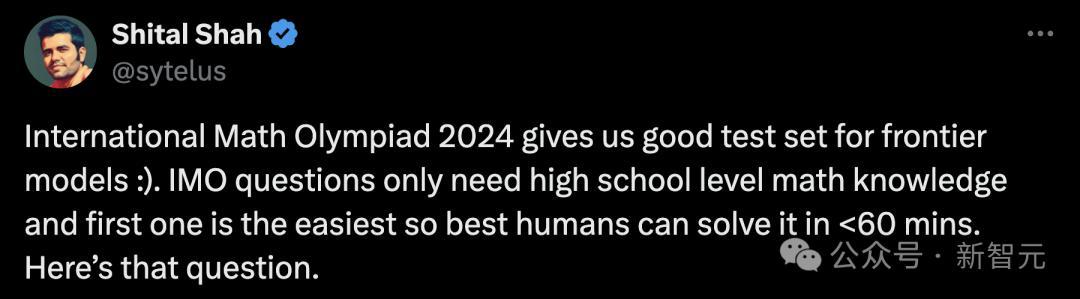
IMO 2024第一题主要检修了实数α的性质,并要求找出知足特定要求的实数α。
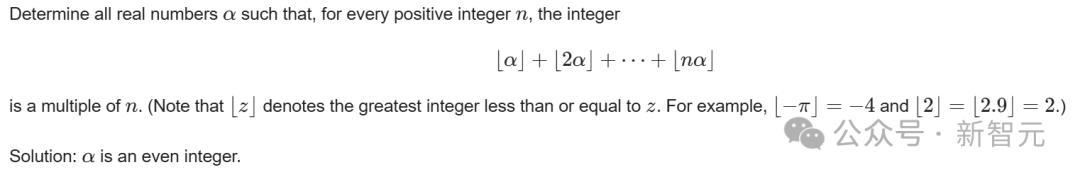
AI给出了正确谜底——α是偶整数。那么,它具体是若何解答的呢?

解题第一步,AI先给出了一个定理,驾驭双方集合格外。
左边集合暗示,通盘知足要求的实数α,对于任何正整数n,n能整除从1到n的⌊i*α⌋;右边集合暗示,存在一个整数k,k是偶数,实数α等于k。
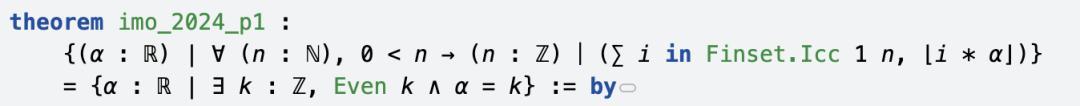
接下来的讲授中,分为两个标的。
最初讲授右边集合,是左边集合的子集(精炼标的)。
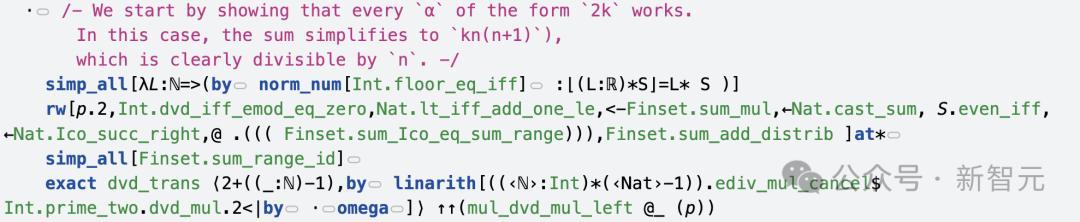
然后,再讲授左边集合,是右边集合的子集(勤恳标的)。

直到代码罢了时,AI建议了一个要道等式⌊(n+1)*α⌋ = ⌊α⌋+2n(l-⌊α⌋),使用等式来讲授α必须是偶数。

终末,DeepMind追思了AI在解题过程中,依赖的三个公理:propext、Classical.choice,以及Quot.sound。

以下是P1的完好解题过程:
https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/imo-2024-solutions/P1/index.html

P2
第二题检修的是,正整数对(a,b)的联系,波及到最大合同数的性质。

AI求解的谜底是:

定理是对于知足特定要求的正整数对(a,b),其集合只可包含(1,1)。
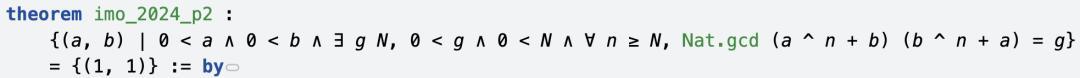
AI在如下的解题过程中,遴选的讲授政策是,最初讲授(1,1)知足给定要求,然后再讲授这是独一的解。
讲授(1,1)是最终解,使用g=2,N=3。

讲授如若(a,b)是解,那么ab+1必须整除g。

在这一过程中,AI使用了欧拉定理,以及模运算的性质进行推理。
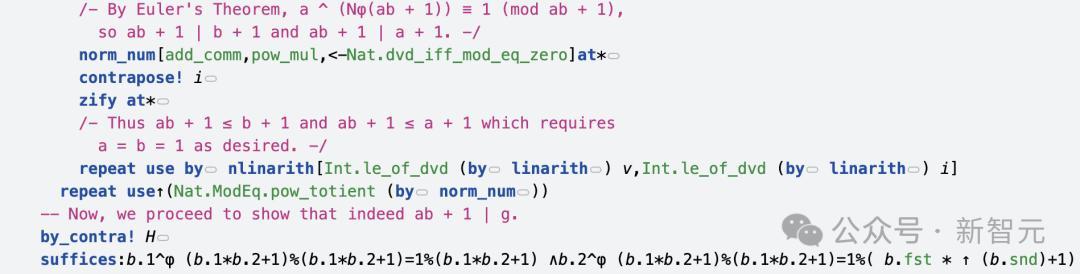
终末,去讲授a=b=1是独一可能的解。

如下是P2的完好解题过程:
https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/imo-2024-solutions/P2/index.html

P4
P4是沿途几何讲授题,要求去讲授一个特定的几何角度联系。

如上所述,这是由AlphaGeometry 2在19秒内完成答题,翻新记录。
凭证所给的惩处决议,与一代AlphaGeometry同样,通盘惩处决议中的补助点齐是由讲话模子自动生成的。
讲授中,通盘的角度跟踪齐使用了高斯消元法(Gaussian elimination),d(AB)−d(CD)等于从AB到CD的有向角度(以π为模)。
解题过程中,AI会手动标注相似三角形和全等三角形对(以红色标注)。
接下来,就是AlphaGeometry的解题设施了,接管了「反证法」去完成。

先用Lean完成需要讲授命题的步地化,以及可视化几何构造。
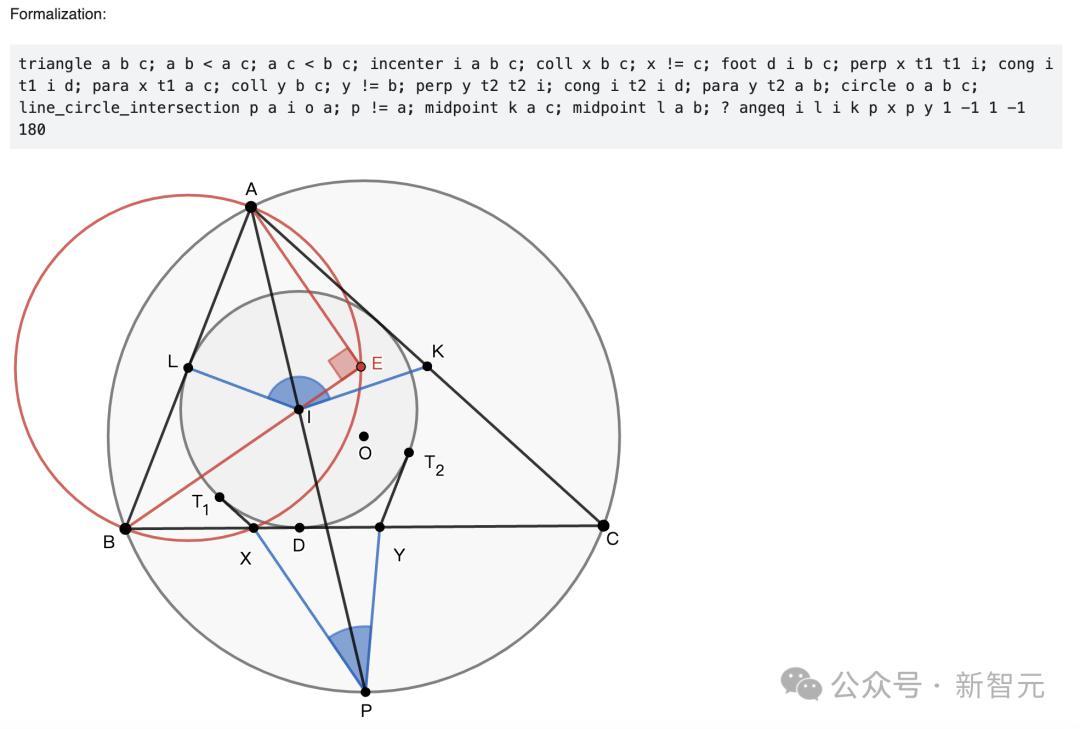
讲授中的要道设施,如下所示。

完好解题过程参见下图:
https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/imo-2024-solutions/P4/index.html

P6
IMO第六题即是「终极boss」,辩论了函数的性质,要求讲授对于有理数的特定论断。
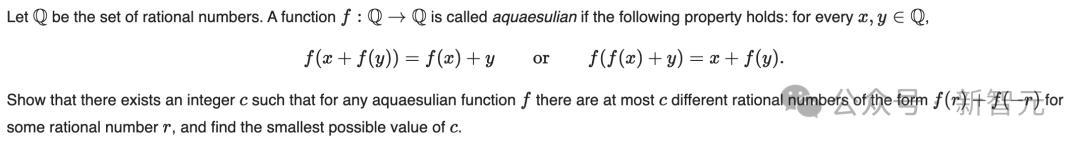
AI求解,c=2。
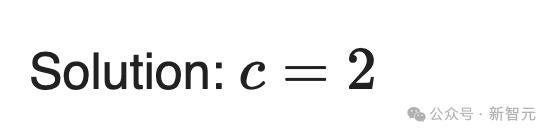
先来看定理声明是,界说了「Aquaesulian函数」的性质,并声明对于通盘这么的函数,f(r)+f(-r)的取值集合最多有2个元素。

讲授政策是,最初讲授对于任何Aquaesulian函数,f(r)+f(-r)的取值集合最多有2个元素。然后构造一个具体的Aquaesulian函数,使得f(r)+f(-r)正值有2个不同的值。

讲授当f(0)=0时,f(x)+f(-x)最多取两个不同的值,并讲授不行能存在f(0)≠0的Aquaesulian函数。

构造函数f(x)=-x+2⌈x⌉,并讲授它是Aquaesulian函数。

终末,再去讲授对于这个函数,f(-1)+f(1) =0和f(1/2)+f(-1/2)=2是两个不同的值。

以下是完好解题过程:
https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/imo-2024-solutions/P6/index.html

能作念奥数题,但能分清9.11和9.9谁大吗?
斯坦福大学和红杉的商量员Andrew Gao深信了此次AI突破的道理——
要道的是,最新IMO试题不包含西宾集合。这极少很迫切,评释AI或者处理全新的、未见过的问题。
并且,被AI得手解出的几何问题,由于波及空间性质(需要直不雅想维和空间瞎想力),历来齐被合计是极具挑战性的。

英伟达高档科学家Jim Fan则发长文暗示,大模子是诡秘的存在——
它们既能在数学奥林匹克竞赛中取得银牌,又会在「9.11和9.9哪个数字更大」这么的问题上频频出错。
不仅是Gemini,就连GPT-4o、Claude-3.5、Llama-3齐无法100%正确回话。

通过西宾AI模子,咱们正在探索杰出自己智能的弘大规模。在这个过程中,咱们发现了一个特殊奇特的区域——一个看起来像地球,却充满诡异山谷的系生人星
这看起来很不对理,但咱们不错用西宾数据溜达来解释:
AlphaProof和AlphaGeometry 2,是在步地化讲授和特定规模的符号引擎上完成西宾。在某种进程上,它们在惩处专科的奥林匹克竞赛问题更出色,即使它们基于通用LLM构建的。
而GPT-4o的西宾集合,混杂了大齐的GitHub代码数据,可能远远跳动数学数据。在软件版块中,「v9.11 > v9.9」,可能严重诬蔑了数据溜达。因此,这个空幻在某种进程上是不错交融的。
谷歌开辟者负责东说念主暗示,或者惩处勤恳的数学、物理问题的模子,是通向AGI的要路阶梯,而今天咱们在这条说念路上又迈出了一步。

另有网友暗示,这一周信息量太大了。
